The Billion-Word Hack: How Word2Vec’s Speed Secret Shaped Its Geometry
Published: November 9, 2025
🧩 Part I: The Computational Crisis and the Brilliant Hack
The Goal: Perfect Word Geometry
A long-standing goal in NLP was to represent words as vectors so that geometric closeness correlates with semantic relatedness. We wanted to encode a word’s meaning into a numerical vector such that Vector Similarity ≈ Semantic Similarity. The closer two vectors in space, the more related their meanings.
The Solution: The Skip-Gram Model
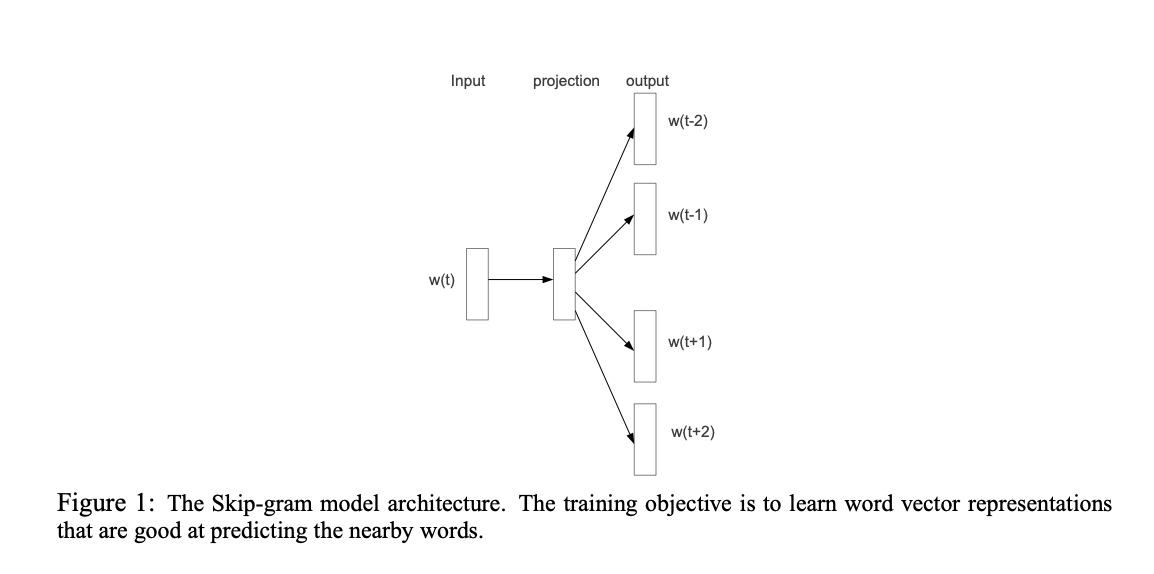
The Skip-Gram model reframed language modeling as a prediction problem: Given a center word ($w_t$), predict its surrounding context words ($w_{t+j}$). The objective is to maximize:
The conditional probability is modeled using the Softmax function:
Here, $v_w$ and $v'_w$ are the “input” and “output” vector representations of $w$, and $|V|$ is the vocabulary size. We will later use only $v_w$ for downstream tasks.
The Bottleneck: The Softmax Tsunami
Computing this softmax denominator scales with vocabulary size ($|V|$ often 10⁵–10⁷), leading to billions of multiplications per update. Training with the full softmax on billion-word corpora was expensive.
The SGNS Hack: Trading Purity for Speed
Tomas Mikolov and colleagues introduced Skip-Gram with Negative Sampling (SGNS), an approximation that replaces the softmax with $K+1$ binary logistic regressions:
Here, negative samples $w_i$ are drawn from a noise distribution $P_n(w)$ (typically $U(w)^{3/4}$). This trick reduced per-update complexity from $O(|V|)$ to $O(K)$—a breakthrough for scalability.
The Binary Decision Layer: Two Sets of Vectors
SGNS learns two distinct embedding matrices: input vectors $v_w$ (words as predictors) and output vectors $v'_w$ (words as predicted contexts). Most downstream tasks use the input embeddings $v_w$.
📐 Part II: The Unintended Consequence — “The Narrow Cone”
In 2017, Mimno & Thompson revealed a geometric anomaly: SGNS embeddings often occupy a narrow cone in space rather than an isotropic (uniform) distribution.
• Isotropic – vectors are uniformly distributed across all directions.
• Anisotropic – vectors cluster in a limited region of space.
• Narrow cone – most vectors share a similar direction, reducing angular diversity.
In the Strange Geometry paper they found:
- Word vectors align along a dominant axis, forming a narrow cone.
- Most input vectors are non-negative in many dimensions.
- Context vectors tend to point in the opposite direction.
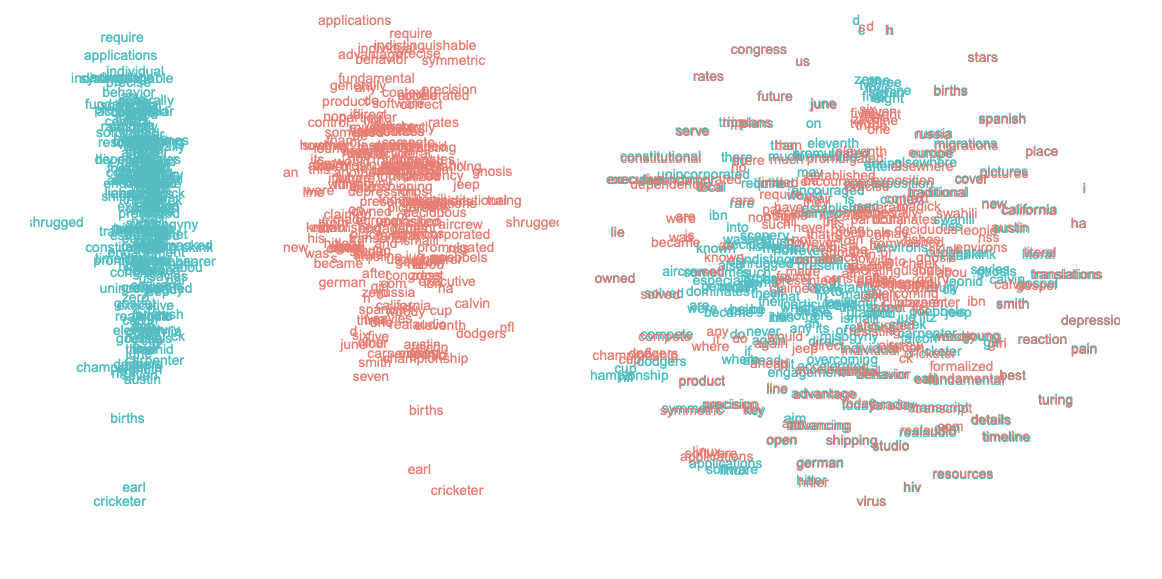
Because vectors share a common global bias direction, cosine similarity becomes less discriminative—it measures small angular deviations rather than large semantic ones. However, as Mimno & Thompson note, SGNS still performs well on many tasks despite this anisotropy. The geometry is thus distorted but functional, not “broken.”
Why Geometry Matters
The geometry of an embedding space directly determines how similarity, clustering, and analogy operations behave. In an isotropic space, cosine similarity captures meaningful relational differences because vectors are spread evenly across directions. In an anisotropic or narrow-cone space, many vectors share similar orientations, making pairwise cosine similarities artificially high even for unrelated words. This can blur semantic distinctions, hurt interpretability, and make downstream classifiers or nearest-neighbor retrieval less sensitive to genuine differences in meaning.
Researchers have found that post-processing steps like removing top principal components or whitening the space (Mu & Viswanath, 2018) can partially restore isotropy and improve performance on similarity and analogy benchmarks. This shows that geometry isn’t just cosmetic it encodes how meaning is organized and compared in the model’s latent space.
The geometry is thus distorted but functional, not “broken” suggests the optimization objective might be encouraging an easier-to-satisfy configuration than the one we intended. This geometric distortion raises deeper questions: Why does an efficient optimization trick yield such a skewed representation—and what does that say about how AI systems pursue proxy goals?
🧭 Part III: An Analogy to Outer Misalignment (Reward Misspecification)
The SGNS story serves as an analogy—not a direct equivalence—to outer misalignment in AI safety: a system optimizes the literal objective but diverges from the intended goal.
| Concept | Applied to SGNS |
|---|---|
| Intended Goal | Learn embeddings where distances reflect semantics well enough for downstream tasks. |
| Proxy Objective | Efficiently minimize the negative sampling loss ($O(K)$ complexity). |
| Observed Outcome | A representation that performs well but exhibits anisotropy. |
| Revised Goal (what researchers later wanted) | Learn a semantically faithful, more isotropic embedding space. |
🚨 Part IV: Lessons for Optimization and Representation
1. The Tyranny of the Proxy
Whenever a complex goal is replaced with a measurable proxy, systems might optimize the proxy even if it subverts the true goal. SGNS’s narrow cone might be the efficient shortcut for its loss function.
2. Interpretability and Asymmetry
SGNS produces two asymmetric spaces ($v_w$, $v'_w$), showing that efficiency-driven optimization can warp internal representations. Understanding such internal “geometry drift” is crucial for interpretability and reliable model design.
The SGNS geometry reminds us that computational shortcuts can reshape representation space itself—a useful cautionary story for both NLP and broader AI systems.
📚 References
- Distributed Representations of Words and Phrases and their Compositionality. PDF
- The Strange Geometry of Skip-Gram with Negative Sampling. ACL Anthology
- All-but-the-Top: Simple and Effective Post-Processing for Word Representations. arXiv
- Understanding Undesirable Word Embedding Associations. ACL Anthology